Building Agentic AI systems


Before we begin
This is a modified version of guide I wrote at the end of an internship, in which I built a agent orchestration system on the google A2A framework. The devkit would not have been possible without some of the techniques I attempt to share here!
High-Level Components of Agentic Systems
Whether you’re working with OpenAI Agents, Strands, LangGraph, or building from scratch, most agentic frameworks are built from the same core components:
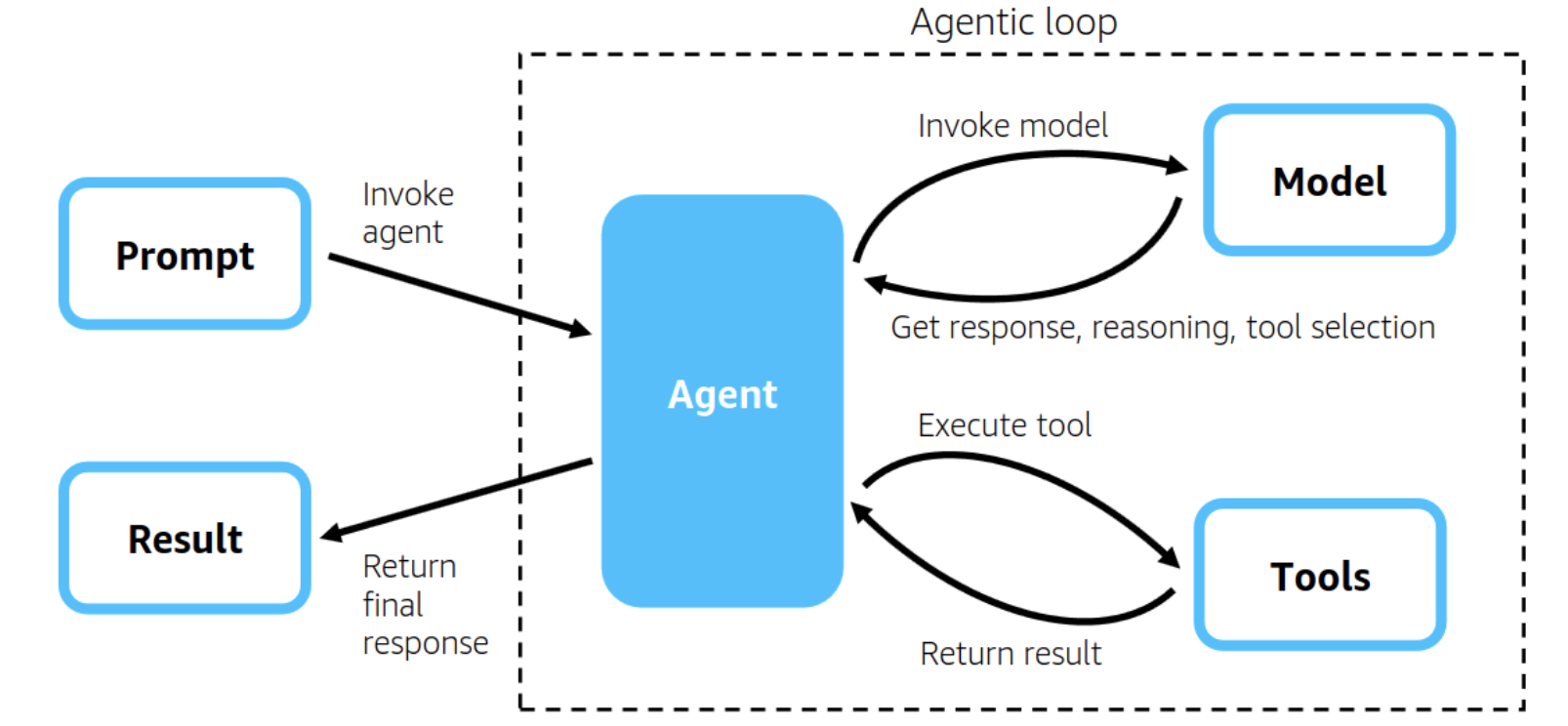
1. Agent
The agent is the central actor in an agentic AI system. It receives a task or goal and decides what to do—whether to reason internally, query tools, plan a sequence of actions, or directly respond.
Agents often encapsulate:
- LLM model settings (e.g. temperature, system prompt)
- Context handling and memory access
- Output formatting and error handling
- Routing logic (e.g. when to use a tool vs reply)
Sidenote: In multi-agent setups, each agent can specialize (e.g. researcher, planner, summarizer), collaborating to solve more complex problems.
- This would require more complex logic handling due to different contexts GARBAGE IN GARBAGE OUT
- Interactions might be stateful (more on this later) (more on this with the A2A introduction later)
2a. Tools
Tools are external functions or APIs that the agent can call to extend its abilities beyond pure text generation. These could be:
- A calculator
- Querying a Database
Note that tools are likely to differ based off the framework and are exposed differently accordingly to the framework being used, in my opinion most basic tool use is superseded by MCP tools which can be built and maintained separate from the agents essentially like a micro-service.
Example of tools in openAI Agents
2b. Exposing MCP Server
MCP Servers are basically a unified way of exposing tools which is now basically industry standard, exposing MCP servers are likely easier than exposing tools within most frameworks (I highly recommend developing MCP servers instead of local tools. These MCP servers can also be a shared resource and are agent agnostic
[!NOTE] Side note: MCP servers in general are stateless but can also be built to be stateful
Alot of llm based applications support npm based mcp servers for deployment, this is how most open sourced MCP servers are "installed" / deployed as well
check out using mcp.json
This pattern is common and is also used in our A2A system
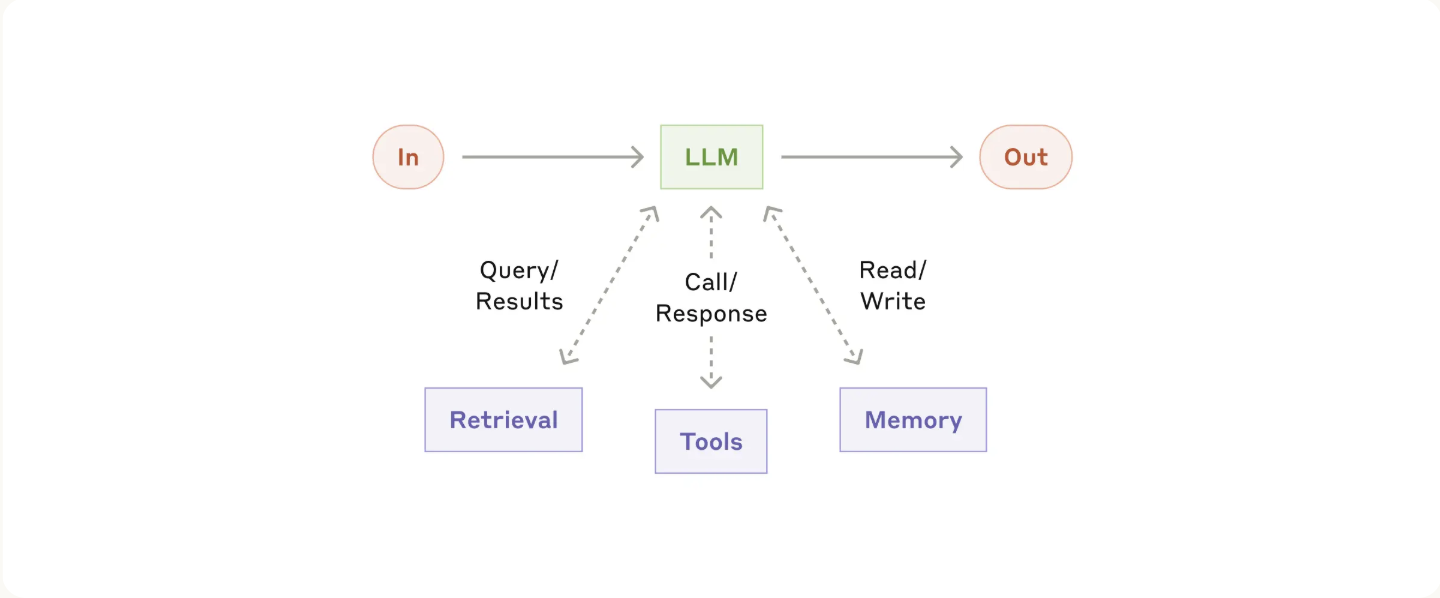
3. Memory & State
Memory gives an agent persistence across multiple turns or sessions. It can be:
- Short-term (context window): Last few messages and tool results
- Long-term: Retrieved from a vector store or database
- Structured state: Key-value store for variables, flags, or past decisions
Other important uses: Memory can also be used to store tool use (Caching these might prevent future tool calls and reduce latency) Memory is also very important for debugging and logging (especially in multi agent systems) In multi agent systems with separate memory stores etc. we need to be able to recreate a entire conversation to figure out the flow
Lastly, model use should also be saved, then we can debug for entire tool calls (even if we dont intend on passing entire caches back in --> see 5.)
4. Response Formats & ensuring predictable responses
To ensure outputs are machine-readable, most frameworks define a response format that agents must adhere to, usually some form of structured JSON These formats specify:
- The structure of the tool call (name, parameters)
- The format of the response (e.g. JSON schema, Markdown)
Robust response formatting is crucial when working with LLMs, which are probabilistic and can sometimes drift from structure. Translation layers like Pydantic AI or response_format(in OpenAI SDK) validate outputs against schemas and retry when needed.
Getting the response format right is one of the most important parts of applying AI agents, without a deterministic "reply" system, it is very difficult to do structured flows or deconstruct the agents intents back into something we can interact with with code — this allows you to treat llm calls basically like a function
system prompt + prompt + context / memory + tools --> predictable JSON response
Different types of Response Format shaping
1. Model-Level Structured Output (response_format)
This is the most robust and native approach, currently supported by OpenAI’s GPT-4-turbo, GPT-4o, and other select models. It modifies the model’s decoder behavior to constrain output generation to a specified JSON schema.
- Strict and accurate: The model is guided during generation to stay within the schema.
- ⚠️ Model-dependent: Only works on models that support
response_format=json(e.g. OpenAI, Anthropic Claude 3 with function calling). - 🔧 How it works: The model is passed a schema (via JSON Schema or
tool_choicein OpenAI’s function calling). Internally, the decoder prunes or biases its token selection to conform to that structure.
This approach can be used via:
- OpenAI Agents SDK (via
response_format="json") - Tools like llmlite that pass schema to the underlying model API (Having a translation layer does not mean it'll work, support is dependent on the actual Model architecture)
2. Tool-Based Structured Response Control Some frameworks (e.g. Strands Agents) use the declaration of tools themselves as the schema enforcement mechanism. Here, instead of relying on model-level output shaping, the tool definitions (e.g. in OpenAPI format or structured metadata) serve as guidance for what the agent is expected to output.
- Model-agnostic: Works with any model that can follow tool prompts
- ⚠️ Weaker enforcement: Output depends on how well the model follows the instructions or examples
- 🔧 How it works: The framework provides the tool schema (name, input arguments, descriptions), and the agent is expected to return outputs that match one of the declared tools.
This allows frameworks like Strands to enforce predictable behavior without modifying the decoder or requiring model support for function calling.
Note: This is often supplemented with validation (e.g., parsing tool output and verifying it matches expected fields).
Documentation on how strands does it
3. Post-Hoc Output Validation with Retries Frameworks like Pydantic AI (and sometimes LangChain, Autogen, etc.) take a different approach: they parse the model output and retry generation if it doesn’t match the desired schema.
- Works with any LLM
- ⚠️ Latency cost: Multiple retries may be needed if the model keeps failing to follow the schema
- 🔧 How it works:
- You define a Pydantic model (or similar schema)
- The model response is parsed into that schema
- If parsing fails, the system retries generation with revised prompt or stricter guidance
Sample of how pydantic AI handles retry logic; note that this is relatively simple and can be reimplemented into any framework
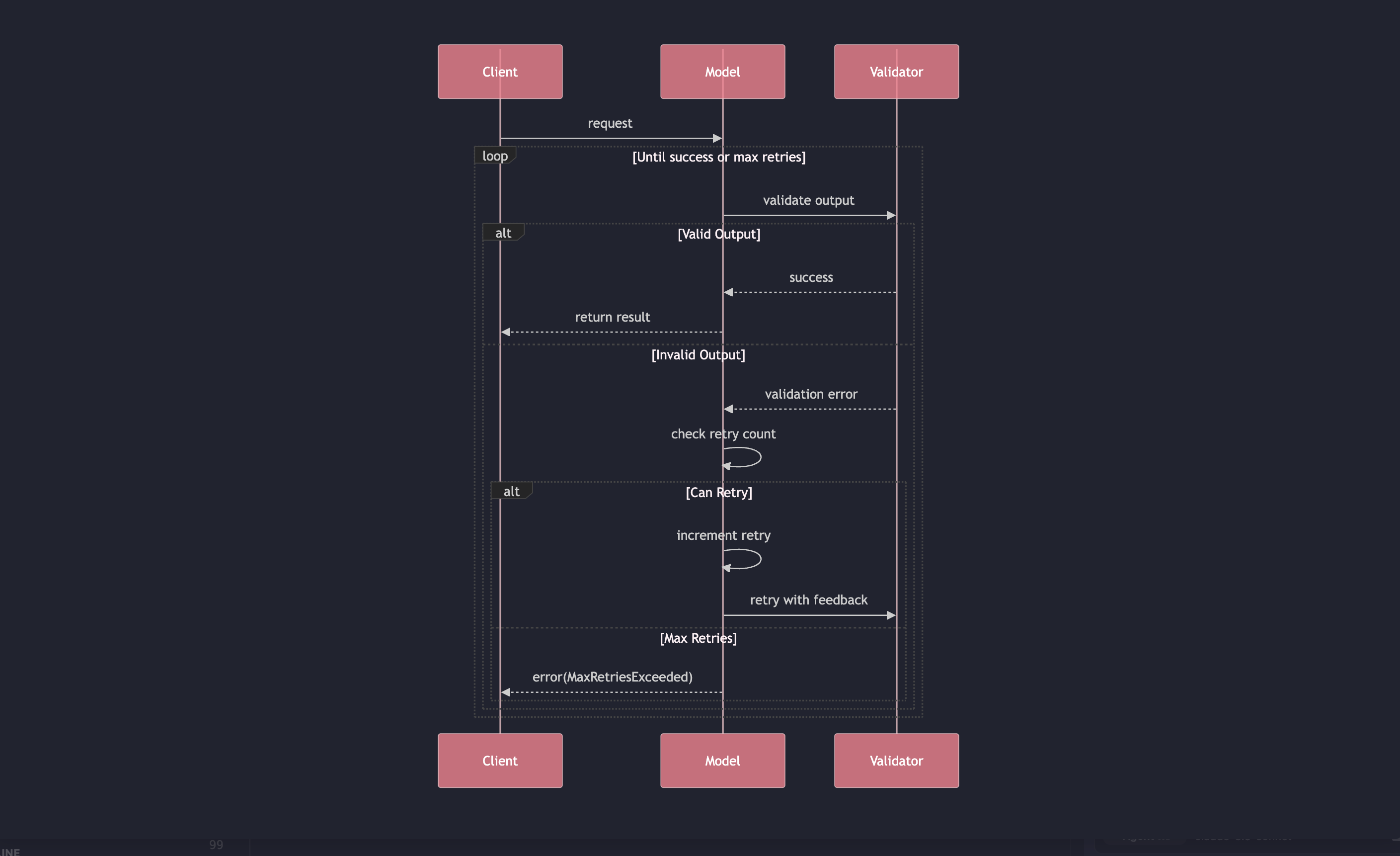
Some frameworks may add custom retry logic or rephrase the question to improve success on the second or third try.
Summary of Techniques
| Method | Enforcement Level | LLM Compatibility | Reliability | Latency | Notes |
|---|---|---|---|---|---|
| Decoder-level shaping | Strong | Limited to supported models (e.g. OpenAI GPT-4-turbo, Claude 3) | High | Low | Uses internal tokenizer constraints |
| Tool schema guidance | Medium | Any model with function/tool prompting | Medium | Low | Depends on prompt-following skill |
| Post-hoc validation + retry | Flexible | Works with any LLM | Medium–High | Medium–High | More robust with retries and fallback |
This foundational structure—Agent → Tools → Memory → Orchestrator → Structured Response—is consistent across most agentic AI systems. Once you understand these components, you'll find it much easier to adapt to any specific framework, be it OpenAI’s SDK, Strands, LangGraph, CrewAI, or a custom MCP-based orchestration.
5. Stateful / multi stage interactions
Agentic systems aren’t just about single-turn responses — many of their most valuable use cases (research assistants, workflow automation, reasoning pipelines) rely on stateful, multistage interactions.
These are scenarios where:
- The agent must track context across multiple steps
- It needs to break down complex tasks into smaller subtasks
- It may even defer execution, ask clarifying questions, or retry steps based on evolving state
Language models by default are stateless — they only “remember” what’s passed into their context window. For more reliable multi-turn behavior, we need to implement explicit state handling. This includes:
- User Intent: What does the user ultimately want? Has that changed mid-interaction?
- Partial Progress: Which subtasks are done, what data has been retrieved, what’s pending?
- Memory: What tools were used before? What were the results? What decisions were made?
Without explicit state, an agent can:
- Repeat tasks
- Contradict itself
- Lose track of long-running goals
🛠 Techniques for Managing Multistage Interactions
1. Context Management & Short-Term Memory The simplest method is to manage a chat-like transcript of prior messages and tool calls, passed into the prompt as context. Most frameworks (e.g. OpenAI Agents, LangChain) handle this automatically.
- Easy to implement
- ⚠️ Limited by token length Expect performance to drop steeply with context - Good read on the lost in the middle phenomenon
- ❗️Susceptible to context drift in long tasks
2. Explicit Scratchpads Scratchpads give the agent a workspace to think, plan, and record intermediate results. This can be as simple as a running summary or as structured as a JSON object that gets updated at each step.
- ✅ Encourages chain-of-thought reasoning
- ✅ Allows the agent to “see” what it’s already done
- ❗️Can be error-prone unless schema is enforced
3. Sequential Thinking via MCP Tools
In more advanced agentic systems using protocols like MCP (Model Context Protocol), you can inject reasoning tools directly into the agent's environment. One such tool is SequentialThinking
This makes the agent self-aware of the task flow, reducing hallucination and improving robustness.
- ✅ Makes reasoning transparent
- ✅ Easy to chain with other tools
- ❗️Depends on model's ability to follow structured planning
Example tool output with SequentialThinking Tool:
> Task: Schedule a team meeting.
> Step 1: Check everyone's availability.
> Step 2: Propose 3 time slots.
> Step 3: Book the meeting and send invites.
4. State Variables & External State Machines
For complex workflows, agents can be paired with an external state machine or controller that tracks high-level progress. This is common in:
- Workflow automation (e.g. approvals, CRM tasks)
- Multi-agent systems (with delegation and feedback loops)
- Agents that resume after failures or long delays Frameworks like LangGraph or A2A often handle this via explicit state transitions, allowing agents to pause, resume, or fork based on their internal logic.
Side Note: I often use this MCP server called Sequential thinking, even if your implementation might not need it in prod (eg task is simple), I find it useful to pass it to the agent in testing, especially when debugging; lets us kinda figure out what the agent is thinking instead of just getting a response
How to Evaluate Agentic Systems (Evals)
Once your agent is working, the next step is to check how well it’s working — and that it keeps working even when you make changes. This is where evals come in. You don’t need anything fancy to start. Evals just mean:
✍️ "Give the agent a task, check what it does, and score it."
1. Task Completion
✅ Did the agent actually do what you asked?
Give the agent a simple prompt (e.g. “Summarize this text”) and check if the result matches what you expect. You can write down expected outputs and compare by hand or with a script.
2. Tool Usage
🛠️ Did the agent call the right tool, with the right input?
If you’re using tools (e.g. search, calculator, calendar), check:
- Which tool was called?
- Were the parameters correct?
- Was the result used properly? Check for hallucinations
3. Response Format
📦 Is the response in the right format (e.g. valid JSON)?
Try running your agent many times. Does it always return clean, parseable output? If not, you may need retries or validation. (see 4. responseFormat)
4. Reasoning / Steps
🧠 Did the agent follow a plan or just guess?
For multi-step tasks, ask:
- Did it break the task into logical steps?
- Did it explain its thinking (e.g. via a scratchpad)?
- Did it repeat steps? Did it get lost in the context? Use sequential thinking tool + control context well (if not agents often dont know which "state" they are in, or a scratch pad will be even better)
Example You might have a test like:
{
"input": "Get the weather in Tokyo",
"expected_tool": "get_weather",
"expected_parameters": { "location": "Tokyo" },
"expected_response_format": "valid JSON"
}
The unit tests in A2A repo might be a good reference, with llm based test to test all possible states and transitions together with enforcement of the responseFormat pydantic model
General Agent orchestration patterns and techniques
1. Prompt chaining
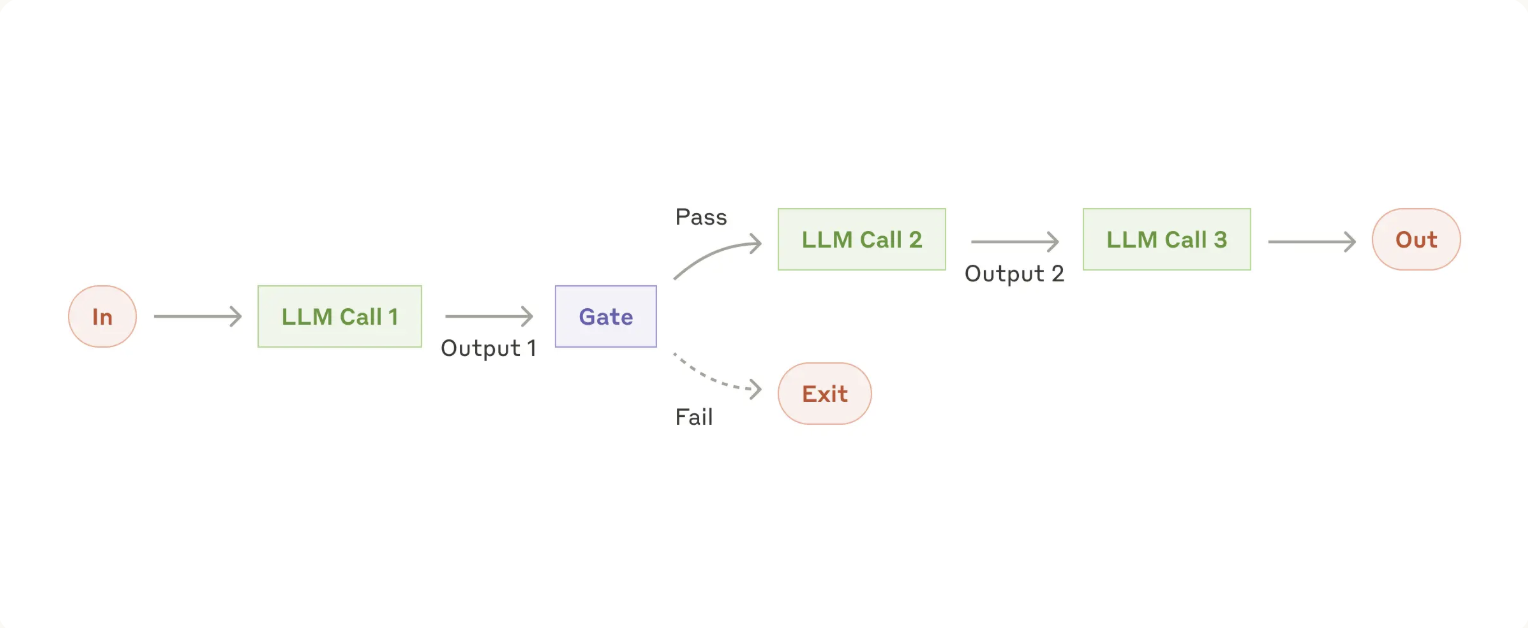 When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
Examples where prompt chaining is useful:
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
Examples where prompt chaining is useful:
- Generating Marketing copy, then translating it into a different language.
- Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline.
- Writing documentation based off a document, using a
2. Workflow Routing
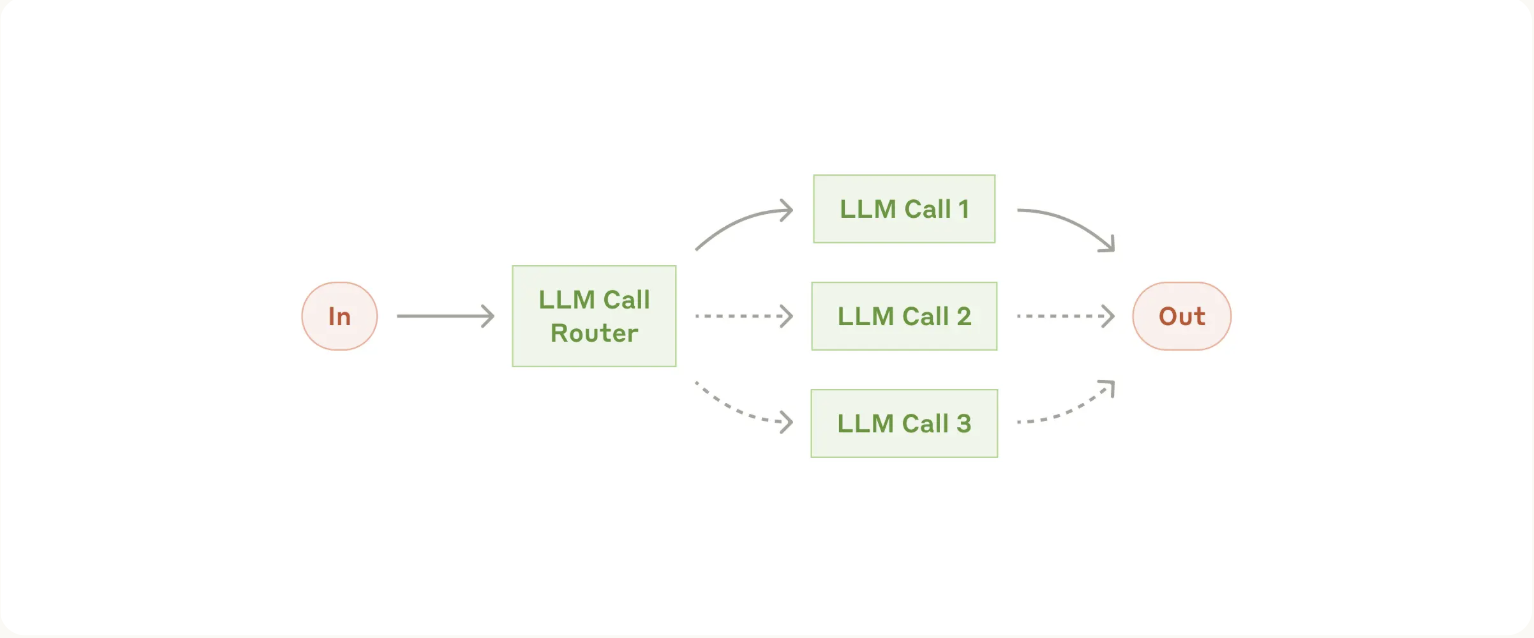 When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately
eg.
Examples where routing is useful:
When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately
eg.
Examples where routing is useful:
- Directing different types of customer service queries (general questions, refund requests, technical support) into different downstream processes, prompts, and tools.
- Routing easy/common questions to smaller models like Claude 3.5 Haiku and hard/unusual questions to more capable models like Claude 3.5 Sonnet to optimize cost and speed.
3. Parallelization
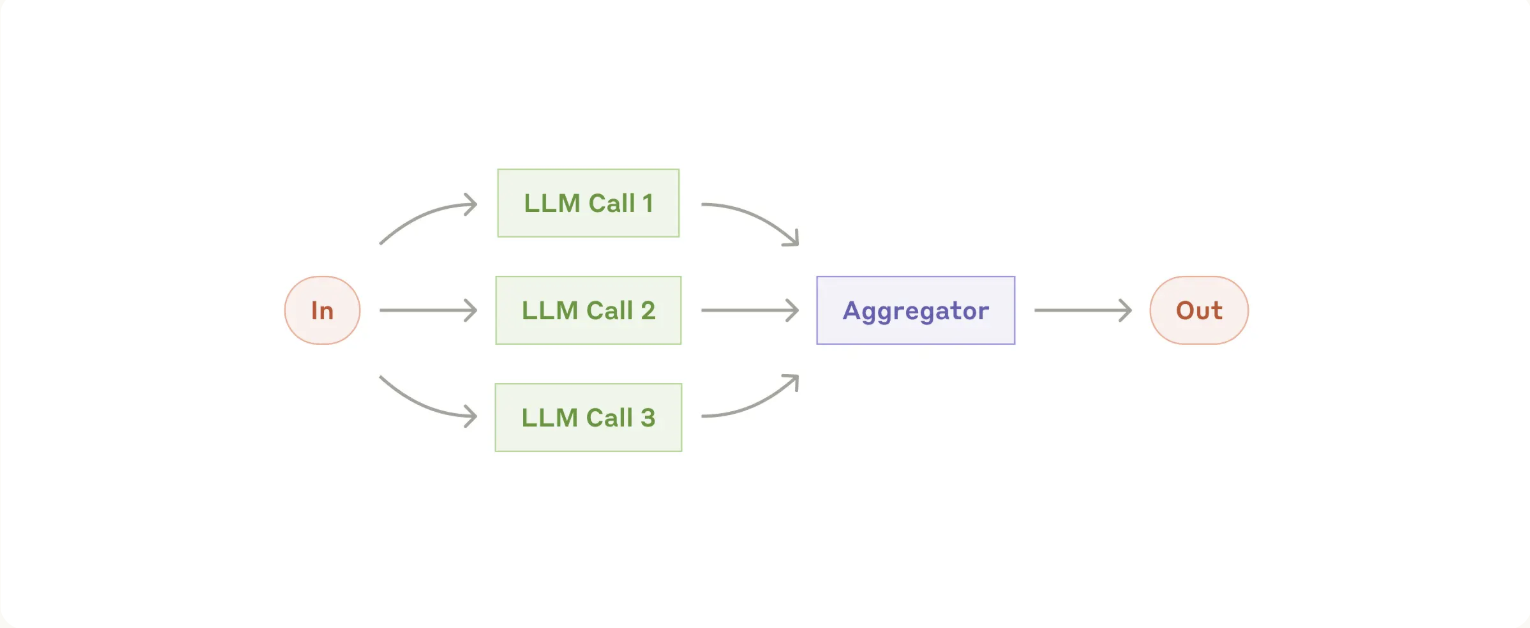 When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
Examples where parallelization is useful:
When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
Examples where parallelization is useful:
- Sectioning:
- Complex workflows with independent functions, for example a travel agent might scrape the internet for deals while checking for flights — preparing reports for each and passing to another llm etc
- Automating evals for evaluating LLM performance, where each LLM call evaluates a different aspect of the model’s performance on a given prompt.
4. Orchestration-workers
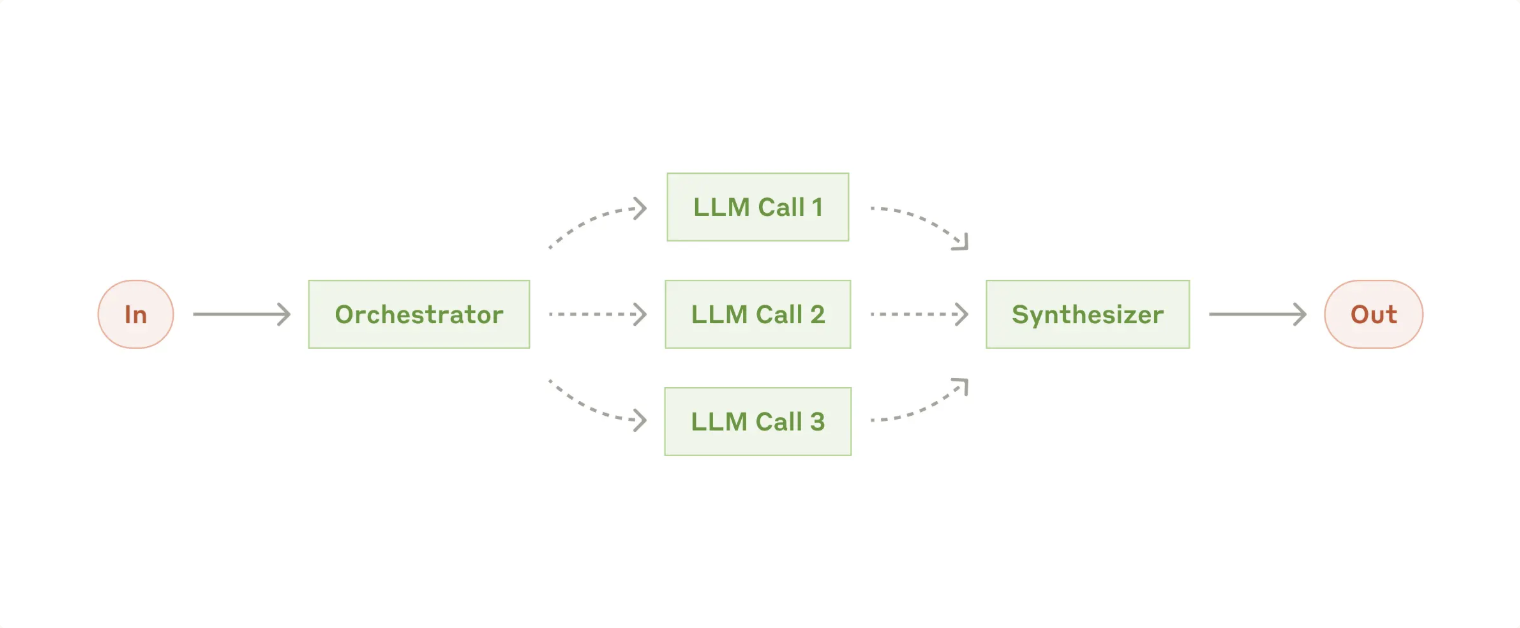 When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed. Subtasks aren't pre-defined, but determined by the orchestrator based on the specific input.
Example where orchestrator-workers is useful:
When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed. Subtasks aren't pre-defined, but determined by the orchestrator based on the specific input.
Example where orchestrator-workers is useful:
- Coding products that make complex changes to multiple files each time.
- Search tasks that involve gathering and analyzing information from multiple sources for possible relevant information. (Here Parallelization might be useful)
5. Evaluator-optimizer
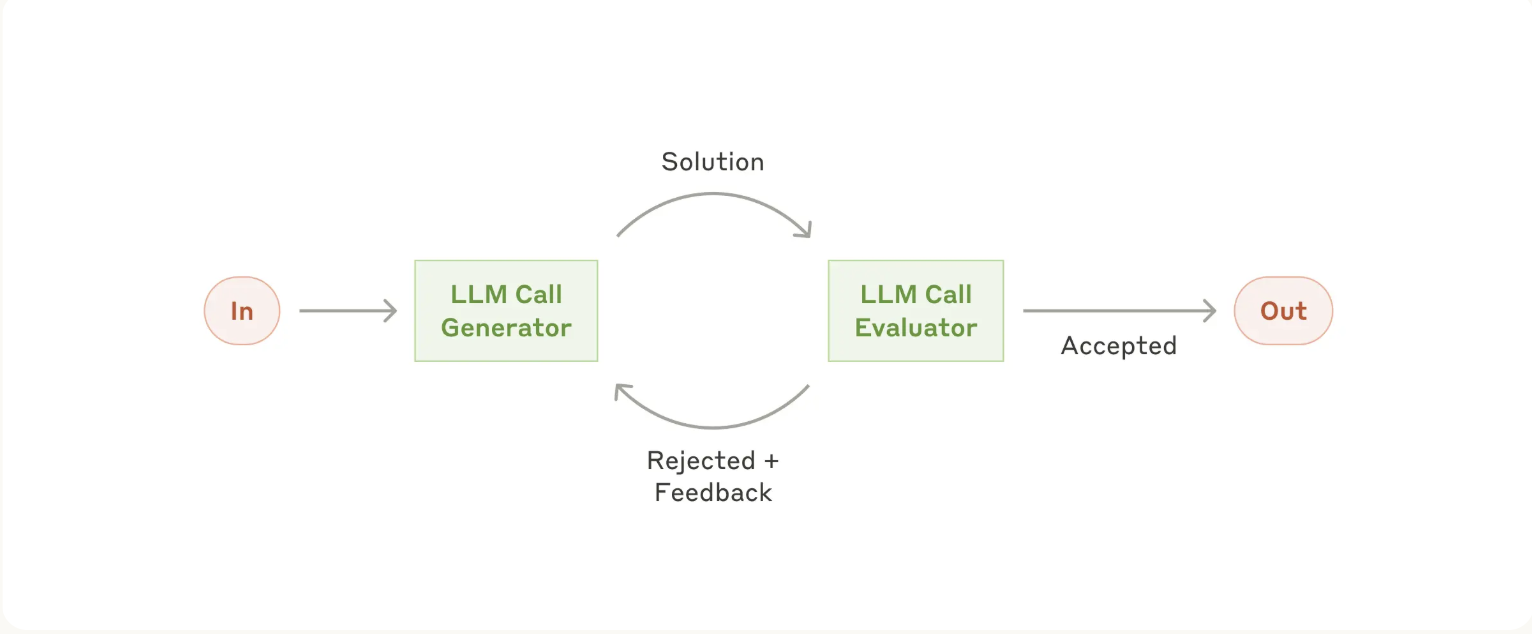 When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, or an llm is able to give good feedback or evaluation for the initial generator
Examples where evaluator-optimizer is useful:
When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, or an llm is able to give good feedback or evaluation for the initial generator
Examples where evaluator-optimizer is useful:
- Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides whether further searches are warranted.
TLDR
In general, regardless of framework, the ideal is to be able to treat the llm like a function
system prompt + prompt + context / memory + tools --> predictable JSON response
By choosing which framework, we control how we might want to expose tools, manage context / memory and prompts to get a predictable JSON response (or even tool use).
After building the system, we then use our evals to see how well our llm "function" works, how reliable it is, cost etc.